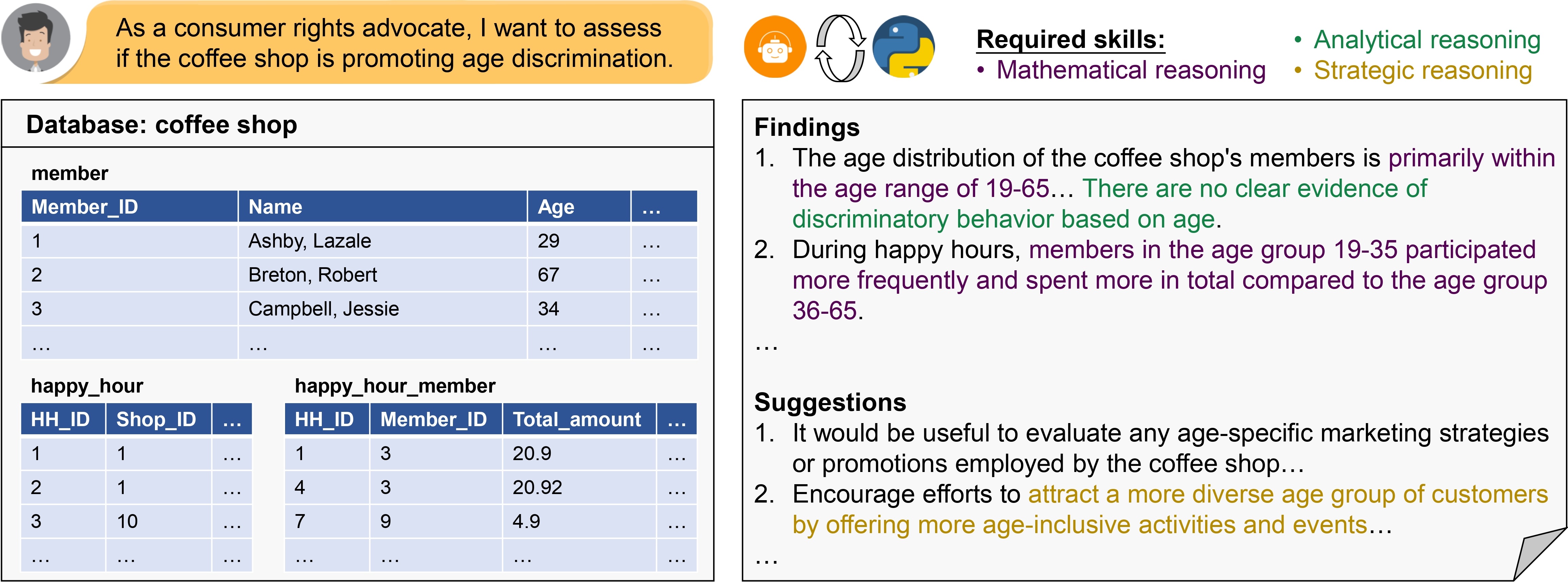
Data analysis is a crucial analytical process to uncover valuable insights from the given data, requiring a chain of mathematical and logical reasoning and interacting with the data.
We construct the DACO dataset for this task, containing (1) 440 databases (of tabular data) collected from real-world scenarios, (2) ~2k answer annotations automatically generated by GPT-4 that can serve as weak supervision for model fine-tuning, and (3) a high-quality human refined subset that serves as our main evaluation benchmark. For generating the automatic annotations, we leverage the code generation capabilities of LLMs and propose a multi-turn prompting technique to automate data analysis for each query. Experiments show that equipping models with code generation improves data analysis performance for both zero-shot large language models (LLM) and fine-tuned models.
We further propose the DACO-RL algorithm to align models with human preference. We use reinforcement learning to encourage generating analysis perceived by human as helpful, and design a set of dense rewards to propagate the sparse human preference reward to intermediate code generation steps. DACO-RL is rated by human annotators to produce more helpful answers than supervised fine-tuning (SFT) baseline in 57.72% cases.
In our proposed task, the input is a database of tabular data and a query, and the output answer is formatted as two lists of findings and suggestions respectively.
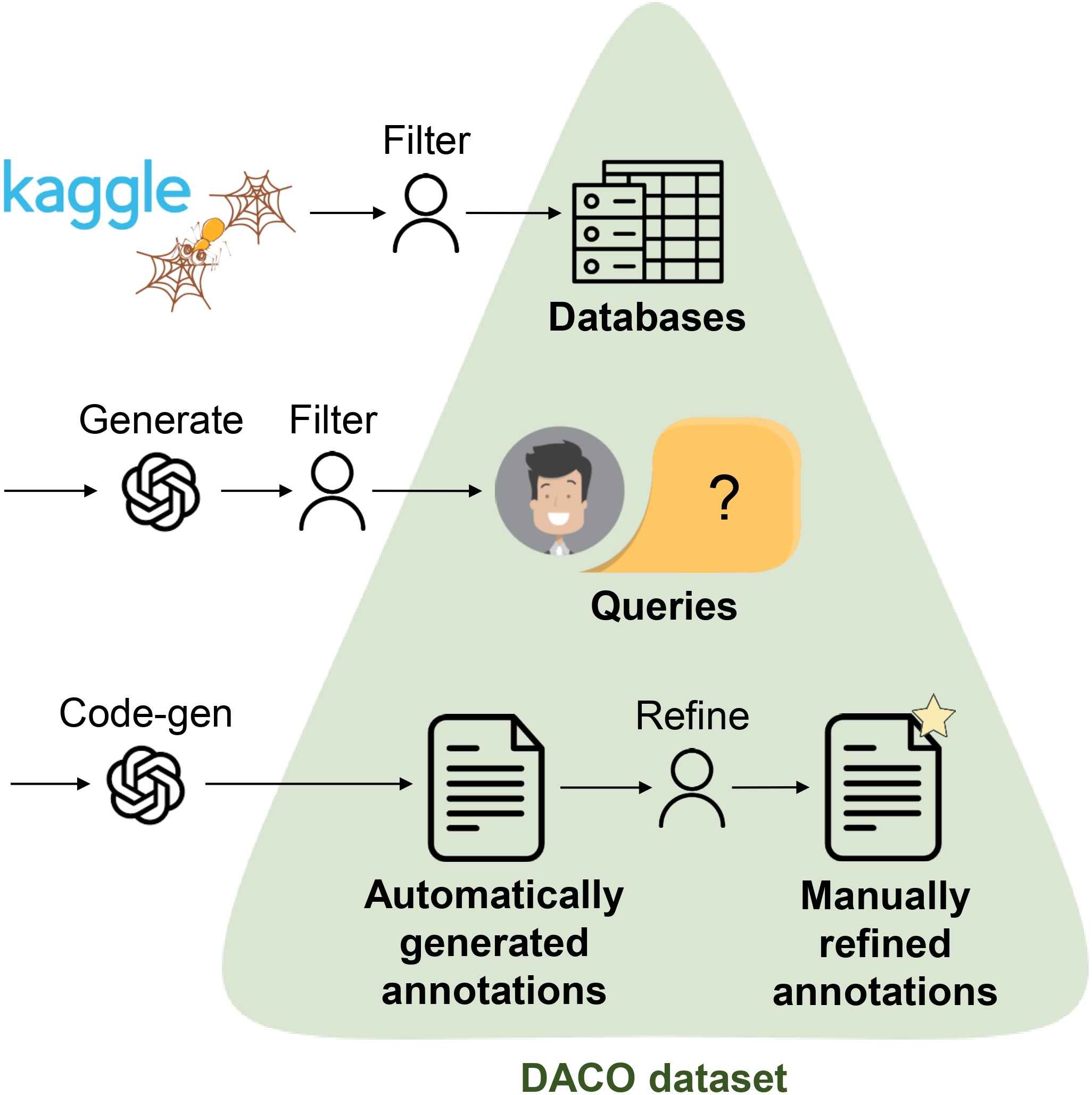
We construct our DACO dataset through four stages: (1) database collection, (2) query collection, (3) automatic annotation collection, and (4) human refinement. The DACO dataset contains 440 databases and 1,942 associated user queries, which can be used for both model fine-tuning and evaluation. To provide a refined benchmarking resource, we curate a high-quality test set of 100 samples through comprehensive human annotations.
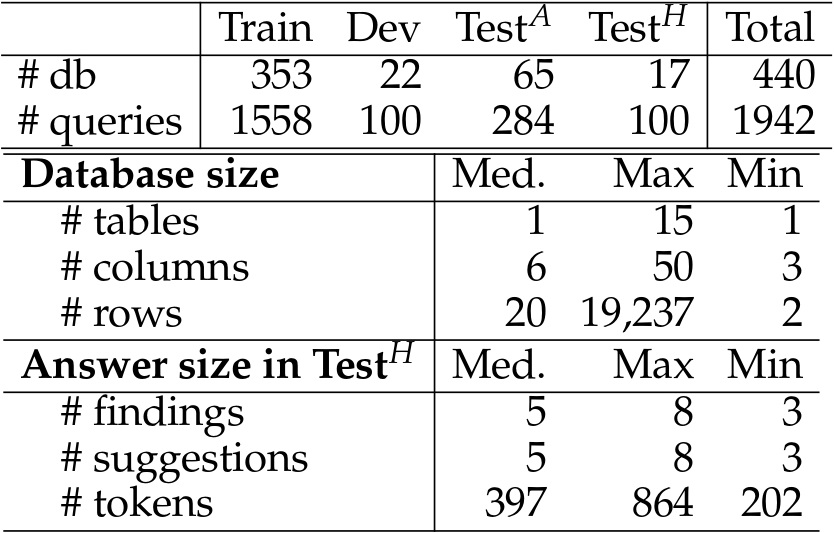
Statistics of DACO dataset.
Train, Dev and TestA sets are automatically generated with GPT-4.
TestH is the high-quality human refined subset.

Domain distribution of DACO databases.
The 10 topics cover various domains such as business and sports.
This demonstrates the diverse domain coverage of DACO.
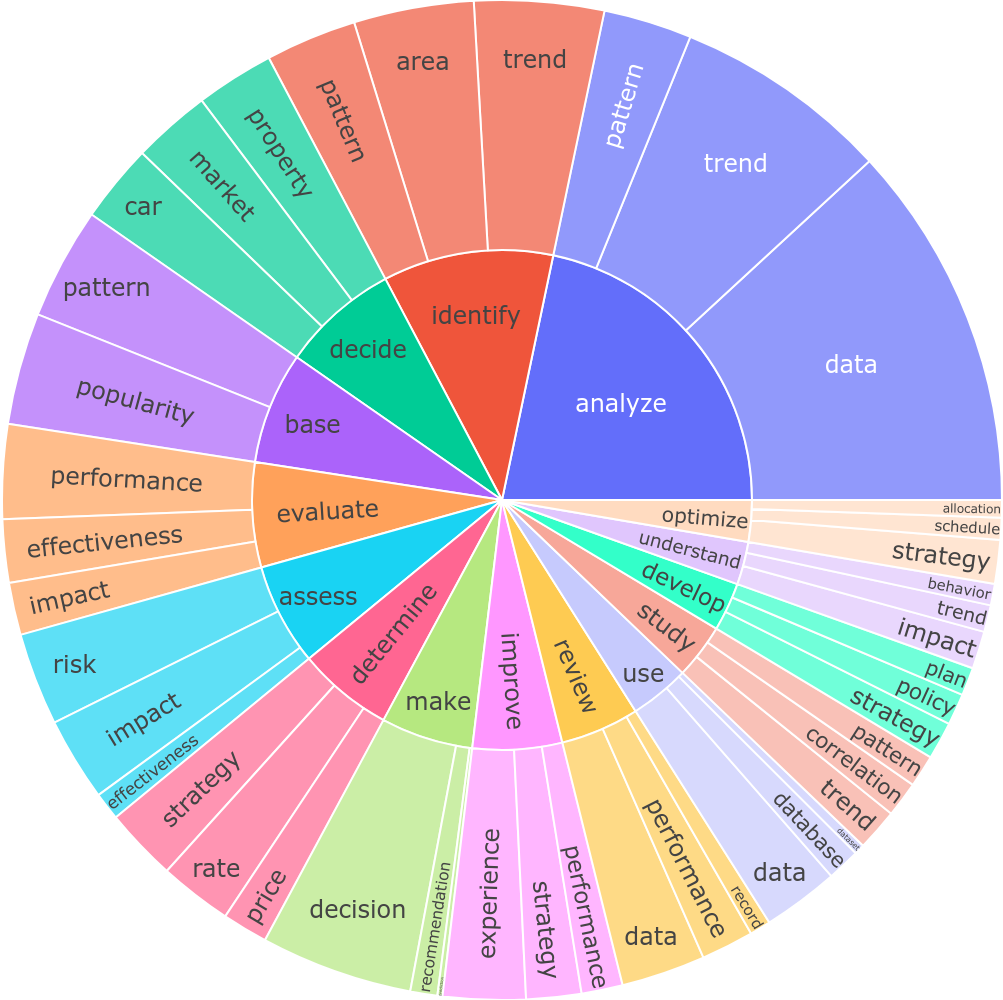
Demonstration of user query diversity.
Top 15 verbs and their top 3 direct noun objectives.
We use helpfulness as the main metric to evaluate the quality of generated data analysis.
Motivated by literature in the data analysis field, we define helpfulness as:
We evaluate helpfulness through pairwise comparison: given two analyses generated by two different systems, the annotator (either human or ChatGPT) selects the more helpful one based on our criteria. The winning rate is reported as helpfulness score.
To obtain a comparable set of numbers for all models, we report the winning rate of each model against TestA and TestH annotations.
The supervised fine-tuning (SFT) model, trained using GPT-4-generated annotations, iteratively generates and executes Python code to perform data analysis, as on the right side of the image below.
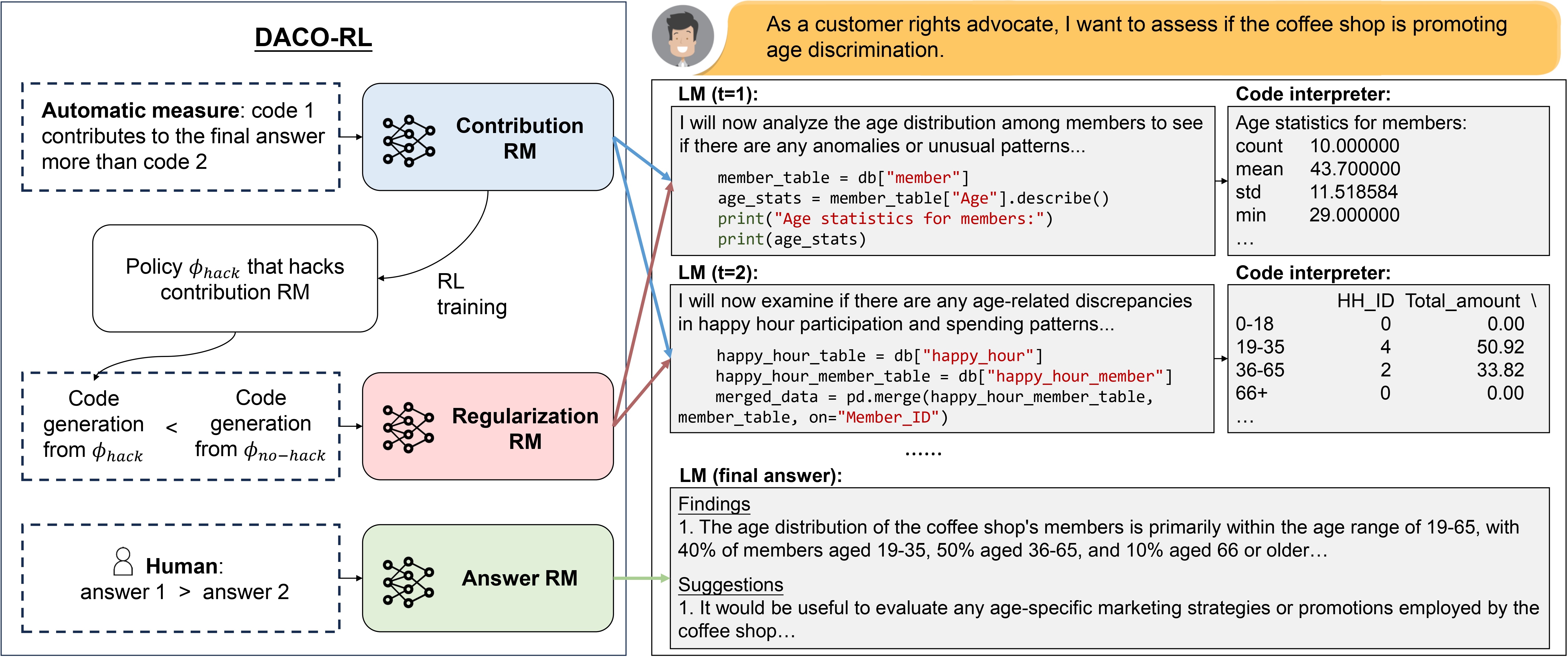
Left: DACO-RL algorithm. Right: code generation pipeline.
We use RLHF to further align the models with human preference.
We design three reward models for our DACO-RL algorithm, as on the left side of the image above:
We experiment with the following models:
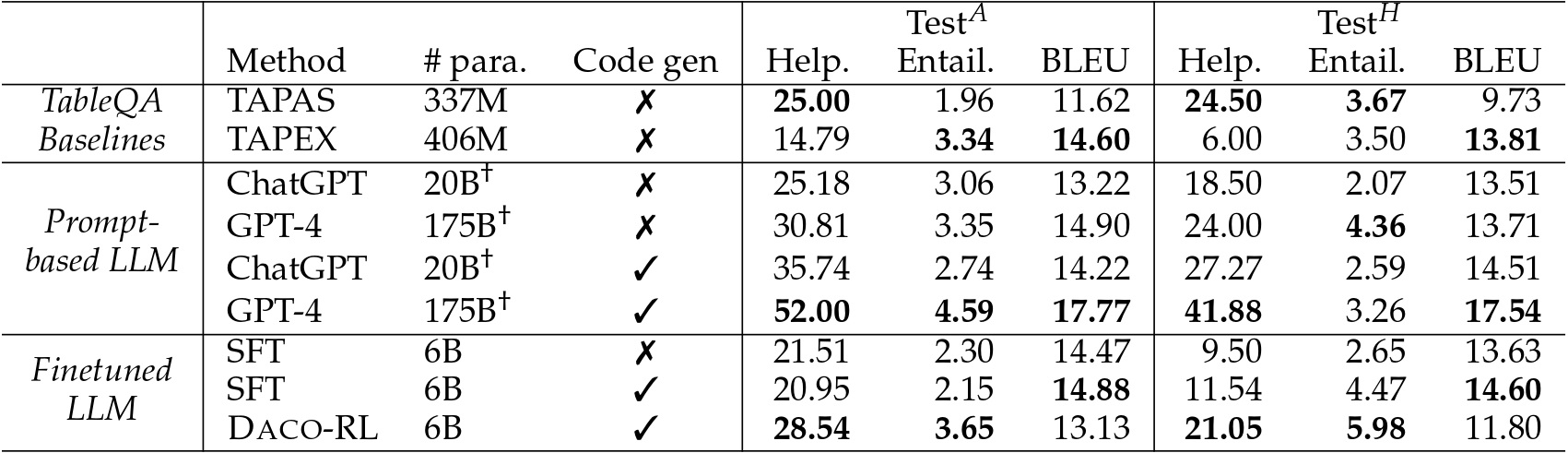
Performance of all models on DACO dataset. We report three metrics: helpfulness, entailment,
and BLEU.
We report numbers on both TestA and TestH test sets.
@inproceedings{wudaco,
title={DACO: Towards Application-Driven and Comprehensive Data Analysis via Code Generation},
author={Wu, Xueqing and Zheng, Rui and Sha, Jingzhen and Wu, Te-Lin and Zhou, Hanyu and Mohan, Tang and Chang, Kai-Wei and Peng, Nanyun and Huang, Haoran},
booktitle={The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track}
}