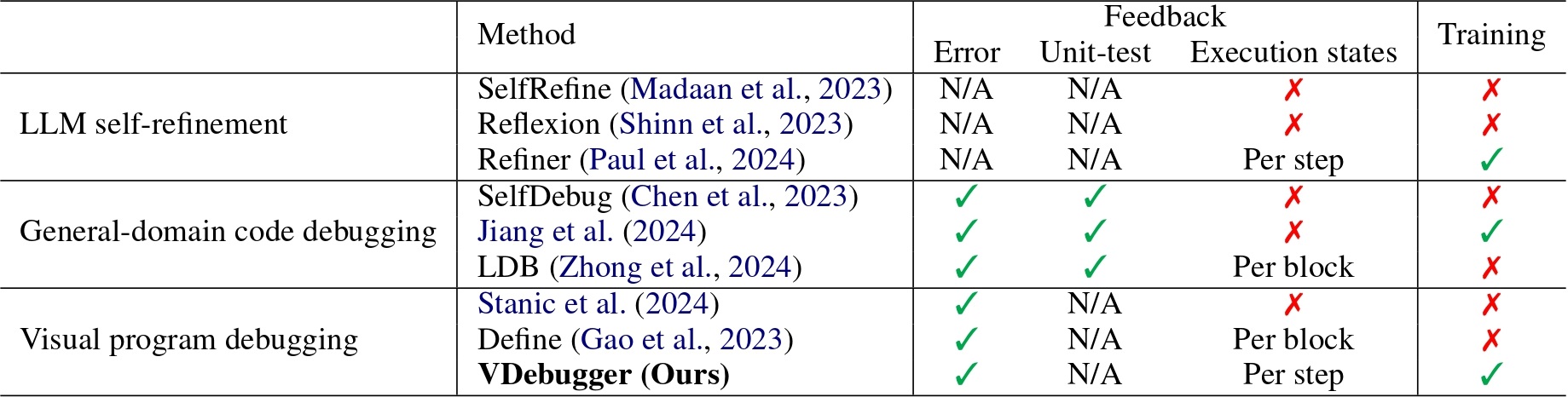
Visual programs are executable code generated by large language models to address visual reasoning problems. They decompose complex questions into multiple reasoning steps and invoke specialized models for each step to solve the problems.
However, these programs are prone to logic errors, with our preliminary evaluation showing that 58% of the total errors are caused by program logic errors. Debugging complex visual programs remains a major bottleneck for visual reasoning.
To address this, we introduce VDebugger, a novel critic-refiner framework trained to localize and debug visual programs by tracking execution step by step. VDebugger identifies and corrects program errors leveraging detailed execution feedback, improving interpretability and accuracy. The training data is generated through an automated pipeline that injects errors into correct visual programs using a novel mask-best decoding technique.
Evaluations on six datasets demonstrate VDebugger's effectiveness, showing performance improvements of up to 3.2% in downstream task accuracy. Further studies show VDebugger's ability to generalize to unseen tasks, bringing a notable improvement of 2.3% on the unseen COVR task.
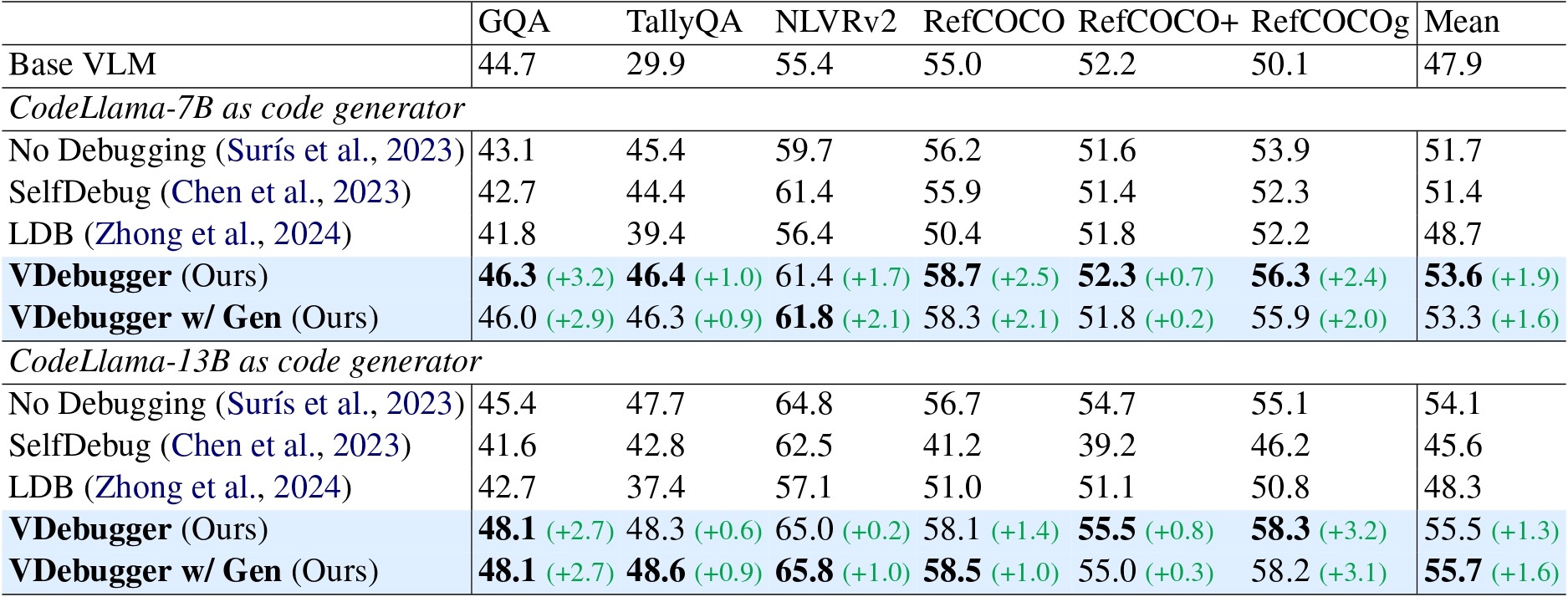
Main results.
The two baselines, SelfDebug and LDB, slightly hurt the performance, while our VDebugger consistently improves the performance in every dataset by up to 3.2% accuracy.
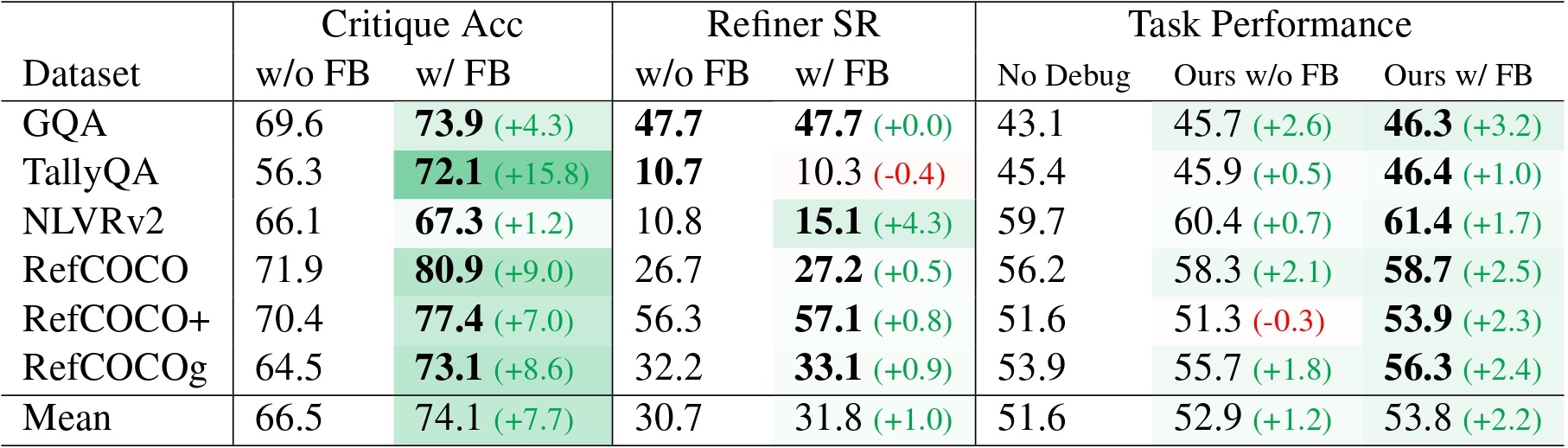
Ablation study.
The critic consistently achieves high accuracy, but the refiner success rate is less reliable.
The execution feedback consistently brings benefits to critic accuracy and the final performance, but the benefits to refiner performance are minimal.
This shows that the remaining challenges mainly lie in correcting the program after the errors are identified.
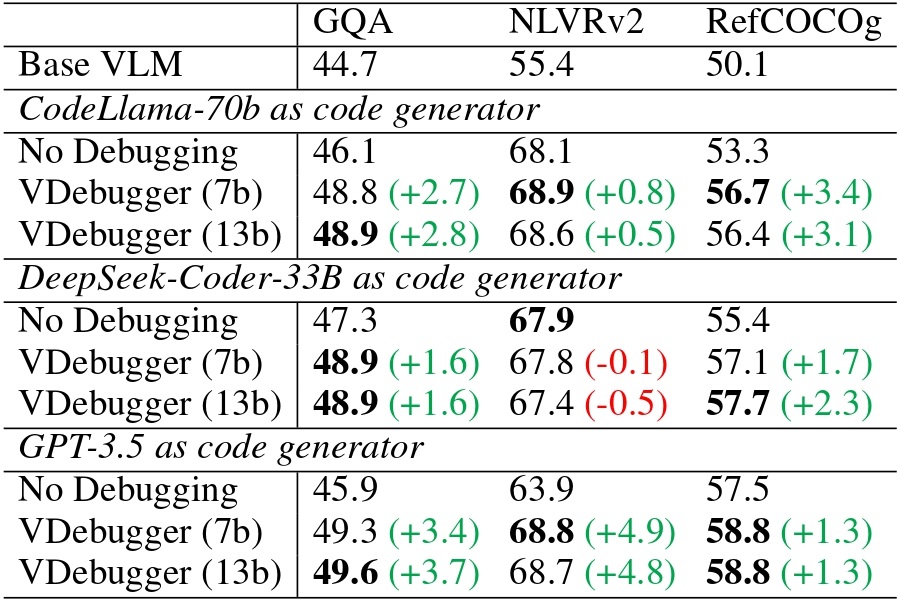
Generalization to unseen LLMs: VDebugger can debug visual programs generated by larger LLMs, including CodeLlama-70b, DeepSeek-Coder-33B and GPT-3.5.
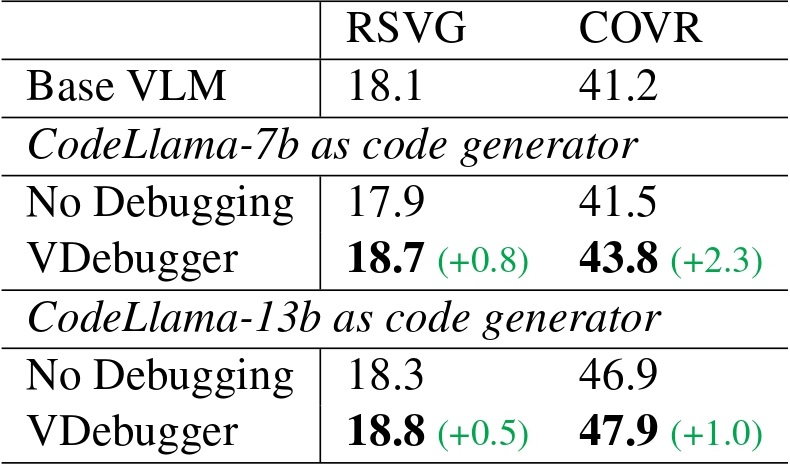
Generalization to unseen tasks: when trained on all six datasets, the generalist VDebugger can generalize to two unseen tasks: (1) RSVG, visual grounding for remote sensing images, and (2) COVR, an unseen task form requiring question answering based on a variable number of images.
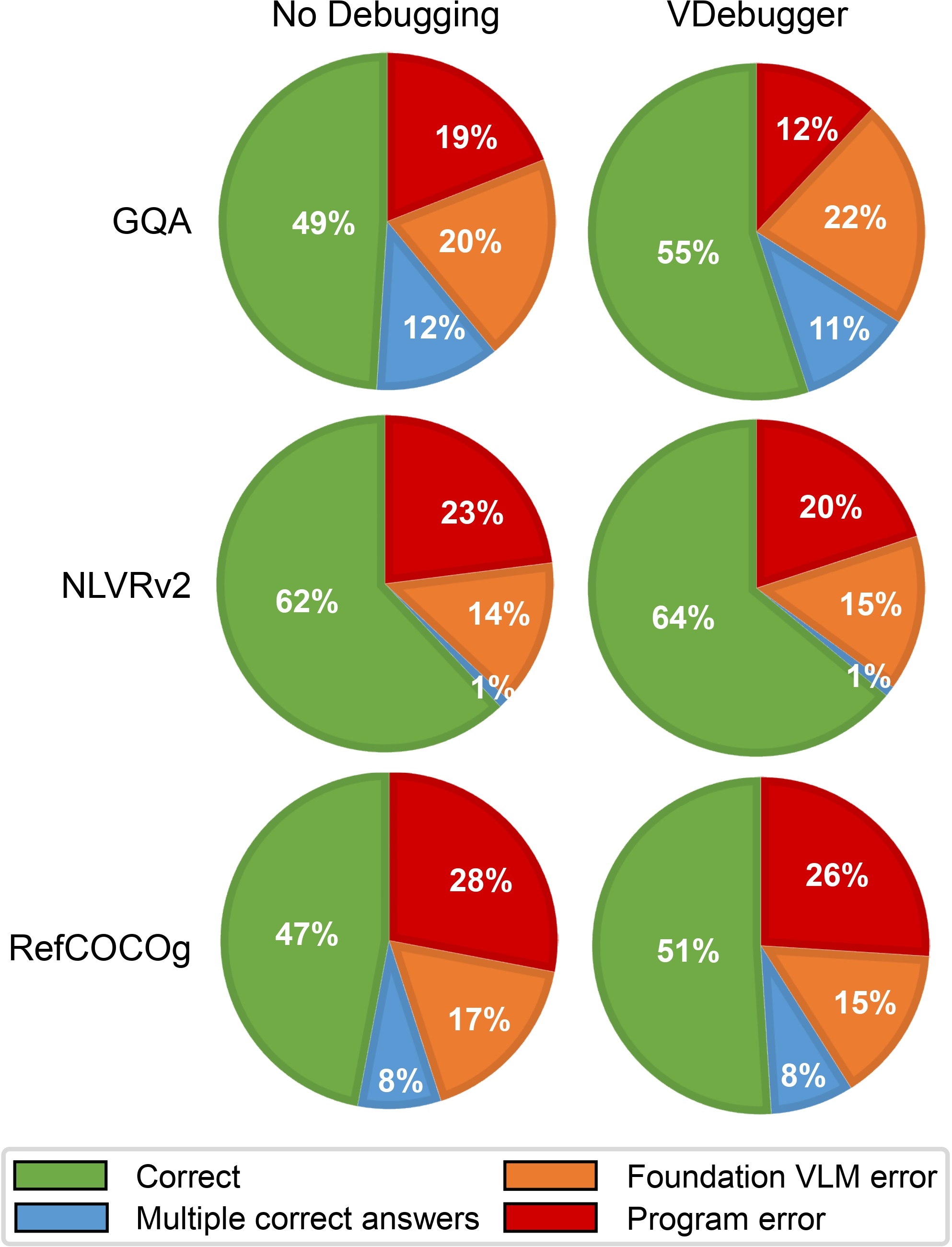
Sources of errors.
Program errors significantly affect the end performance. VDebugger consistently reduces program errors on all datasets, and can also help recover from foundation VLM errors especially on RefCOCOg.

Example where VDebugger fixes program error.

Example where VDebugger recovers from foundation model error.
The question answering model yields incorrect
answer "vanity" in the original program. By detecting this error, VDebugger invokes the foundation VLMs in an alternative way
and thus obtains the correct answer.
@inproceedings{wu-etal-2024-vdebugger,
title = "{VD}ebugger: Harnessing Execution Feedback for Debugging Visual Programs",
author = "Wu, Xueqing and
Lin, Zongyu and
Zhao, Songyan and
Wu, Te-Lin and
Lu, Pan and
Peng, Nanyun and
Chang, Kai-Wei",
editor = "Al-Onaizan, Yaser and
Bansal, Mohit and
Chen, Yun-Nung",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2024",
month = nov,
year = "2024",
address = "Miami, Florida, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-emnlp.575",
doi = "10.18653/v1/2024.findings-emnlp.575",
pages = "9845--9860"
}